Learning Scenarios in Machine Learning - Various approaches to how models learn and are evaluated based on the availability, type, and sequence of training data.
Actions
Table of contents
Open Table of contents
Supervised Learning
Supervised learning is a task where a computer learns a function that maps inputs to outputs based on a dataset of input-output pairs. [2]
Under supervised machine learning approach there are multiple ways, like classification, regression and so on. Following is an example of classification, with loss function calculations. Learn more…
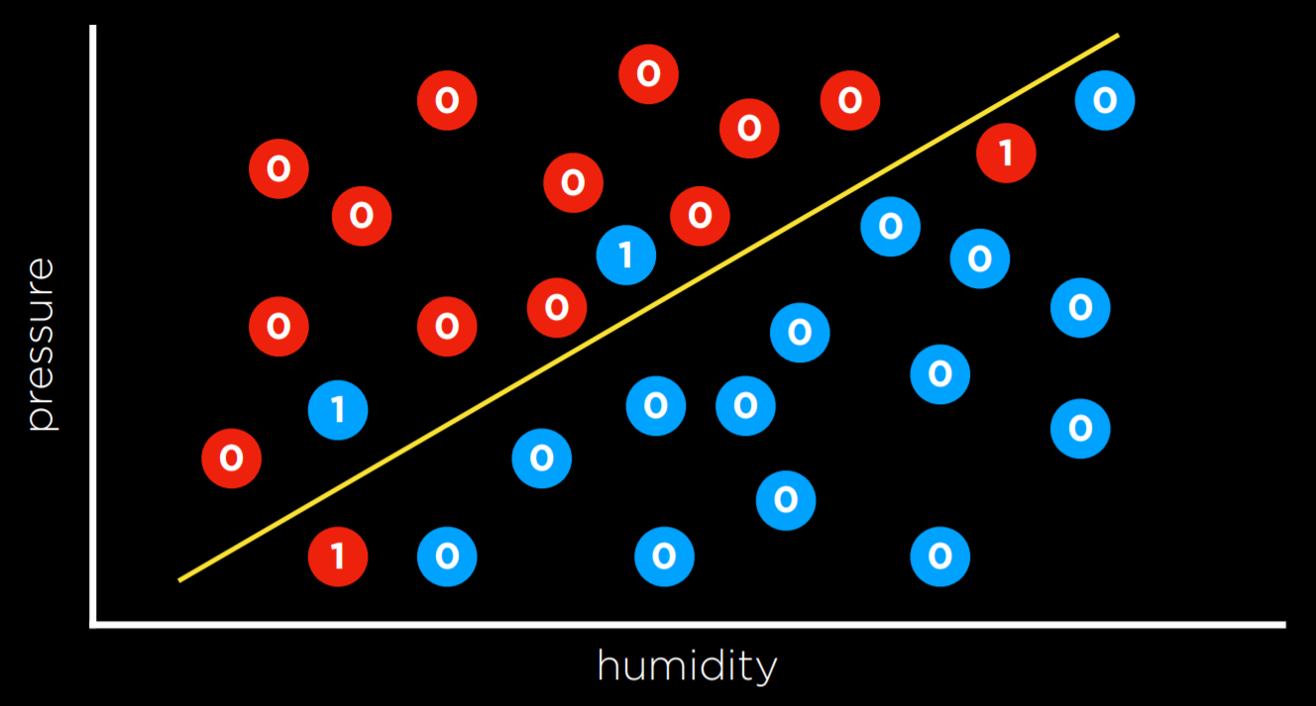
The learner receives a set of labeled examples as training data and makes predictions for all unseen points. This is the most common scenario associated with classification, regression, and ranking problems. The spam detection problem discussed in the previous section is an instance of supervised learning. [1]
- Learner receives labeled examples as training data.
- Used in classification, regression, and ranking problems.
- Goal: Make predictions for unseen points.
Unsupervised Learning
In all the cases we saw before, as in supervised learning, we had data with labels that the algorithm could learn from. For example, when we trained an algorithm to recognize counterfeit notes, each banknote had four variables with different values (the input data) and whether it is counterfeit or not (the label). In unsupervised learning, only the input data is present and the AI learns patterns in these data. [2]
Following is the example of k-means clustering. Learn more…

The learner exclusively receives unlabeled training data, and makes predictions for all unseen points. Since in general no labeled example is available in that setting, it can be difficult to quantitatively evaluate the performance of a learner. Clustering and dimensionality reduction are example of unsupervised learning problems. [1]
- Learner works only with unlabeled data.
- Difficult to evaluate performance due to lack of labeled data.
- Examples: Clustering, dimensionality reduction.
Reinforcement Learning
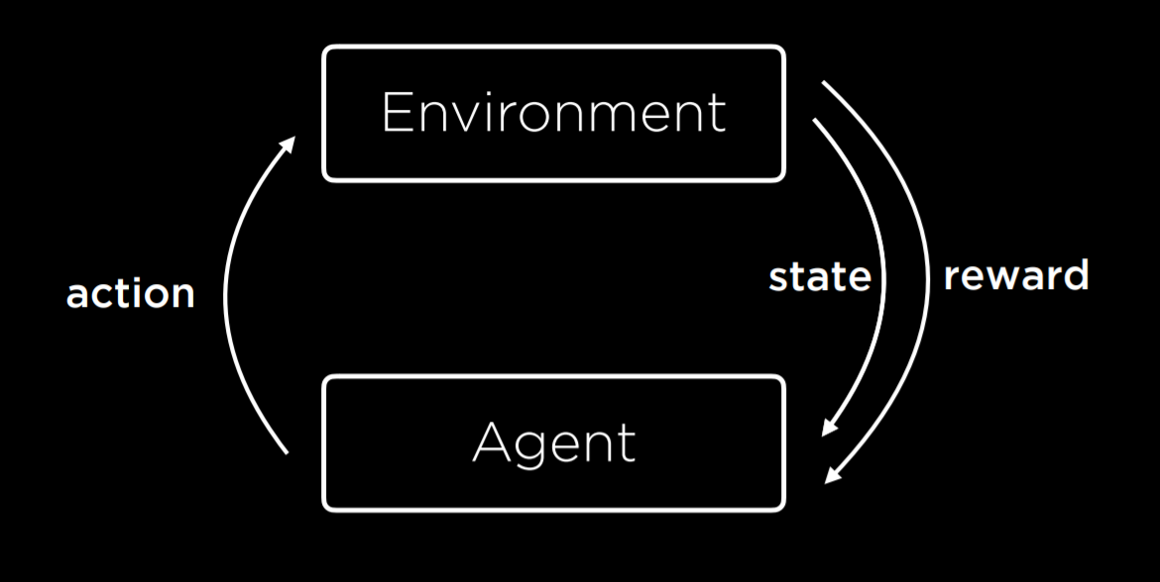
Reinforcement learning is another approach to machine learning, where after each action, the agent gets feedback in the form of reward or punishment (a positive or a negative numerical value). [2]
The learning process starts by the environment providing a state to the agent. Then, the agent performs an action on the state. Based on this action, the environment will return a state and a reward to the agent, where the reward can be positive, making the behavior more likely in the future, or negative (i.e. punishment), making the behavior less likely in the future. [2]
This type of algorithm can be used to train walking robots, for example, where each step returns a positive number (reward) and each fall a negative number (punishment). Learn more…
The training and testing phases are also intermixed in reinforcement learning. To collect information, the learner actively interacts with the environment and in some cases affects the environment, and receives an immediate reward for each action. The object of the learner is to maximize his reward over a course of actions and iterations with the environment. However, no long-term reward feedback is provided by the environment, and the learner is faced with the exploration versus exploitation dilemma, since he must choose between exploring unknown actions to gain more information versus exploiting the information already collected. [1]
- Learner interacts with an environment and receives immediate rewards for actions.
- Goal: Maximize cumulative reward over interactions.
- Faces the “exploration vs. exploitation” dilemma—balancing gathering new information vs. using existing knowledge.
Other Paradigms
Semi-supervised Learning
The learner receives a training sample consisting of both labeled and unlabeled data, and makes predictions for all unseen points. Semisupervised learning is common in settings where unlabeled data is easily accessible but labels are expensive to obtain. Various types of problems arising in applications, including classification, regression, or ranking tasks, can be framed as instances of semi-supervised learning. The hope is that the distribution of unlabeled data accessible to the learner can help him achieve a better performance than in the supervised setting. The analysis of the conditions under which this can indeed be realized is the topic of much modern theoretical and applied machine learning research. [1]
- Learner uses a mix of labeled and unlabeled data.
- Common when unlabeled data is abundant but labeled data is expensive.
- Aims to improve performance by utilizing the distribution of unlabeled data.
Transductive Inference
As in the semi-supervised scenario, the learner receives a labeled training sample along with a set of unlabeled test points. However, the objective of transductive inference is to predict labels only for these particular test points. Transductive inference appears to be an easier task and matches the scenario encountered in a variety of modern applications. However, as in the semi-supervised setting, the assumptions under which a better performance can be achieved in this setting are research questions that have not been fully resolved. [1]
- Similar to semi-supervised, but the focus is on predicting labels for specific test points.
- Considered easier than general supervised learning tasks.
- Common in modern applications, but its performance assumptions are still under research.
On-line Learning
In contrast with the previous scenarios, the online scenario involves multiple rounds and training and testing phases are intermixed. At each round, the learner receives an unlabeled training point, makes a prediction, receives the true label, and incurs a loss. The objective in the on-line setting is to minimize the cumulative loss over all rounds. Unlike the previous settings just discussed, no distributional assumption is made in on-line learning. In fact, instances and their labels may be chosen adversarially within this scenario. [1]
- Involves multiple rounds of learning with intermixed training and testing phases.
- At each round, a prediction is made for an unlabeled point, followed by receiving its true label and a loss.
- Objective: Minimize cumulative loss over rounds.
- No assumptions about data distribution; data may be chosen adversarially.
Active Learning
The learner adaptively or interactively collects training examples, typically by querying an oracle to request labels for new points. The goal in active learning is to achieve a performance comparable to the standard supervised learning scenario, but with fewer labeled examples. Active learning is often used in applications where labels are expensive to obtain, for example computational biology applications. [1]
- Learner queries an oracle to request labels for specific points.
- Goal: Achieve performance similar to supervised learning with fewer labeled examples.
- Often used in cases where labeling is costly (e.g., computational biology).
References
- Mohri, Mehryar, et al. Foundations of Machine Learning. United States, MIT Press, 2018. (Page: 7, Section: 1.4)
- CS50’s Introduction to Artificial Intelligence With Python. cs50.harvard.edu/ai/2024. (Week 4: Learning, Section: Notes)